[Paper Review] Sequence to Sequence Learning with Neural Networks
Paper Review for Seq2Seq model
들어가기 앞서, 이 글은 저의 Notion에 있던 paper review를 재구성한 것으로, 일부 목록을 chatgpt 를 사용하여 재구성되었습니다. 따라서 어색한 문구나 적절하지 않은 설명이 존재할 수 있으니, 양해 부탁드리며, 알려주시면 감사하겠습니다.
1. Introduction
DNN 은 매우 강력한 모델이며, CNN 이나 speech recognition 등을 파악할 수 있다. 하지만, DNN 은 Input, Output 채널이 유한한 차원을 가져야 한다는 명백한 한계점이 있기도 하다. 예를 들면 speech recognition 이나 machine translation 같은 것들은 sequential 하기 때문에, DNN 만으로 문제를 해결하기에는 어렵다.
이 논문에서는 하나의 LSTM을 input sequence 를 입력받아 dimensional vector 로 표현하게 할 것이며, 또 다른 하나의 LSTM 을 이용해서 그 벡터로부터 output 을 extract 하도록 할 것이다.
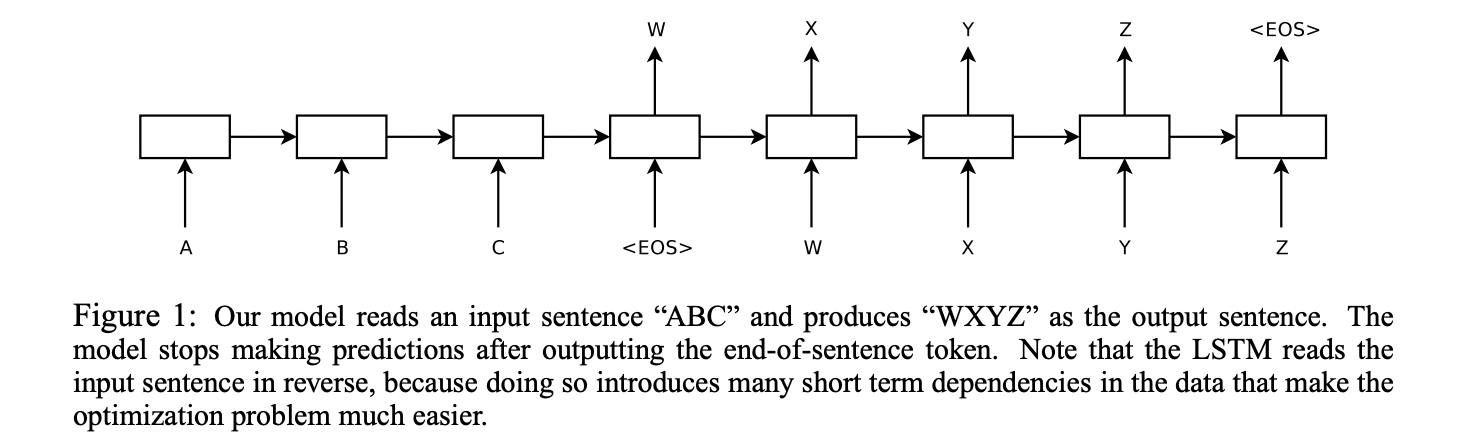
위의 사진과 같이 A B C 라는 문장을 EoS, (End-of-Sentence) 를 추가하여 학습하고, 이를 다시 sequence 한 words 로 무제한 출력하는데, EoS 가 나올때까지 반복한다.
한 가지 중요한 technique 으로는, Train sentence 들을 reverse 해서 넣은 것이다. 왜 reverse 해서 넣는지는 엄밀한 설명이 불가하지만 (어느 정도 결과론적), 아래 예시를 살펴보면 직관적으로 이해가 가능하다.
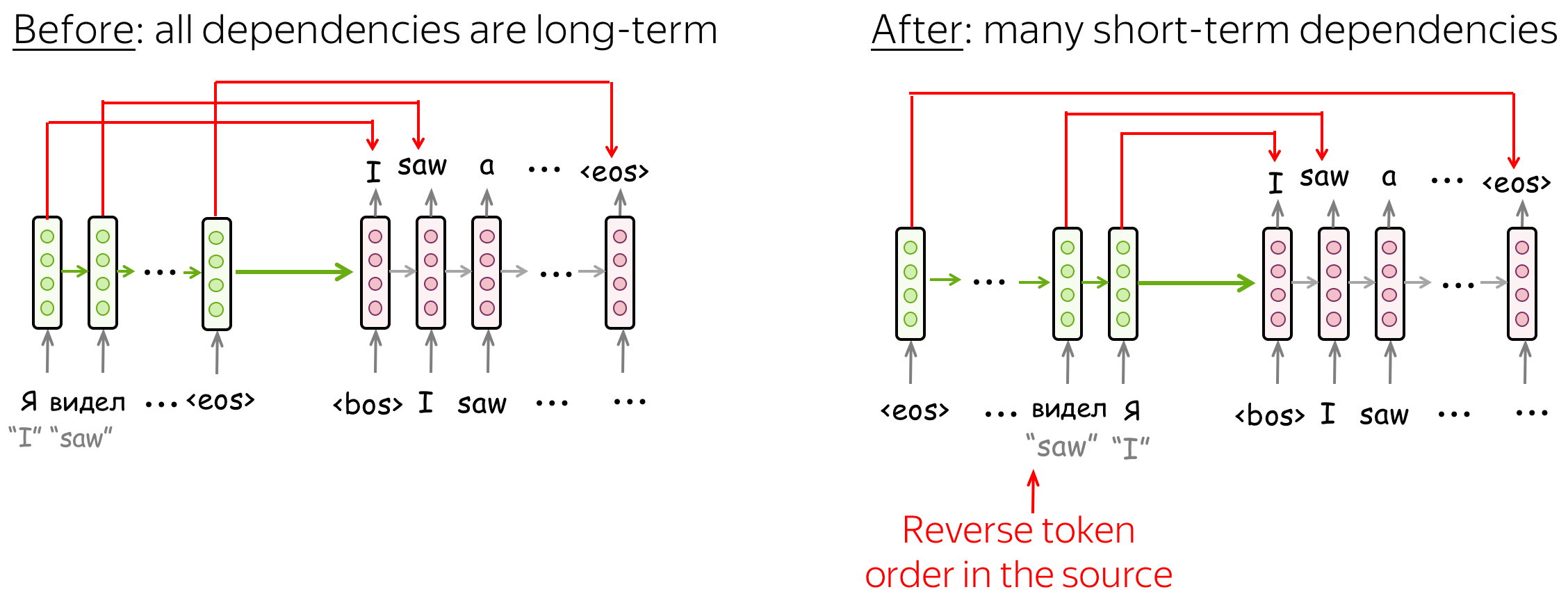
위 그림과 같이, 원래대로 단어를 배열하게 되면, 모든 단어가 같은 간격으로 가중치를 부여받는데, 반대로 할 경우 첫번째 단어가 서로 가장 가까이 있기 때문에, 정보 손실 없이 첫번째 단어를 높은 정확도로 추측할 수 있다.
물론 “가장 마지막 단어는 그러면 틀릴 가능성이 너무 높다.” 라고도 반박할 수는 있겠지만, LSTM 은 recurrent 한 모델이기에, output 부분의 앞의 정확도가 높다면 뒤의 정확도도 높을 것이라는 발상 또한 가능하다.
(놀랍게도, 본 논문에서 제안된 모델은 이전의 모델과 구조가 유사함에도 불구하고, long sentence 에 대한 번역 정확도가 떨어지지 않았다고 한다.)
LSTM의 유용한 속성으로, input sentence 를 받아서 (가변 길이의) 하나의 finite-dimensional vector 로 표현이 가능하다는 점이 있다. 이는 번역을 할 때 문장을 그대로 직역하는 것이 아니라 의역해야 한다는 점, 문장 자체의 의미를 파악해야 한다는 점을 감안해, 유사한 의미의 문장은 가까운 벡터로, 다른 의미의 문장은 먼 벡터로 표현된다. (이 모델이 단어의 순서를 파악하고, 수동태와 능동태에 구애받지 않는다는 점은 이를 뒷받침해주는 정성적 평가일 것이다.)
2. The Model
RNN 은 input 과 output 에 대한 alignment를 알고 있다면, 다른 모델들에 비해 Seq2Seq 작업을 손쉽게 수행할 수 있다. 하지만, 만약 Input과 Output 의 길이가 다르고, non-monotonic relationship 들로 복잡한 구조로 되어 있는 문장의 경우는, 정확도가 현저히 줄어들게 된다.
가장 간단한 전략은, input-sentence 를 하나의 fixed-dimension vector 로 매핑한 후에, 이 벡터를 이용해서 output sequence 로 추출하는 것이다. RNN 모델은 모든 단어에 관련된 정보들을 제공받기 때문에 가능하지만, 문장의 길이가 너무 길어지게 되면, 그 관련 정보가 너무 희석될 수 있다.
반면, LSTM (Long-Short Term Memory) 은 이런 RNN의 근본적인 문제를 해결할 수 있기 때문에, 본 논문에서는 LSTM 을 이용하여 Encoding-Decoding 기법으로 모델을 구성하였다.
이 LSTM 모델의 목표는, 아래의 조건부 확률을 에측하는 것이다.
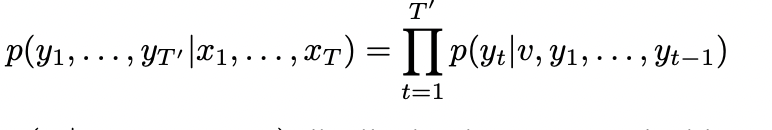
입력 데이터 x1, x2, ,… xT 가 주어졌을 때, y1, y2, … yT’ 가 나올 확률이 곧 이 모델의 정확도가 되겠다.
여기서 주의할 점은, T 와 T’ 은 같은 길이가 아니라는 것, 그리고 각 입력 단어들은 reversed 형태로 학습된다는 것이다. 그리고, 이렇게 reversed 된 단어 sequence 로 학습하게 되면, 추후에 SGD 를 이용해서 연산할 떄, “establish communication” 이 가능해져 더욱 효율적이다.
- Establish-communication (QSGD) 관련 설명
QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
3. Experiments
이 논문에서는 WMT’14 의 Eng to French 데이터셋을 이용하여 2가지 방법으로 접근했다. SMT system 의 reference 를 사용하지 않고 바로 direct translate 한 것과, SMT system 의 n-best list 를 참고하여 rescoring 한 것이다. 따라서 이 두가지 방법들에 대해 accuracy 를 계산했고, 기존의 traslation 방식과 더불어 이 방식들을 시각화하였다.
3.1 Dataset details
앞서 언급했듯이, WMT’14의 Eng to French 데이터셋을 이용했다.
이 데이터셋 중에서 [29] 논문으로부터 clean 하게 선택된 subset을 사용하였는데, 12M 개의 문장과, 348M 개의 프랑스어, 그리고 304M 개의 영어 단어가 포함되어 있었다. (이 데이터를 이용한 이유는, 이 데이터셋이 SMT 1000-best list 내에 포함되어 있는 토큰화된 공공 데이터셋이였기 때문이다.)
더 나아가 일반적인 언어 모델은 각 word의 vectorize 에 의존하게 되는데, 이 논문에서는 두 언어에 대해 고정된 vocab을 사용하였다. 160000개의 가장 빈번하게 나온 영어단어, 그리고 80000개의 가장 빈번하게 나온 프랑스 단어를 사용하여 학습을 진행했고, 이 vocab 에 포함되지 않은 단어들은 모두 UNK 라는 토큰으로 표현했다.
3.2 Decoding and Rescoring
이 실험의 중점은 large & deep LSTM 을 많은 문장 쌍들에 대해 학습시키는 것이다. 이 모델을 측정할 수 있는 방식으로 log probability를 최대화시키는 방식을 사용했다. 그 식은 아래와 같다.
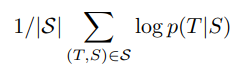
S 가 선택되었을 때, 제대로 된 T 가 나올 가능성을 모두 log 함수로 적용해 더해주게 되면, 모두 log 내로 곱해져 전체적인 조건부 확률이 되는 것을 생각할 수 있다 !
이렇게 학습이 종료되고 나면, Beam Search 를 이용하여 가장 translation 에 적합한 문장을 생성해냈다.
Beam Search 는 각각의 LSTM 에서 확률이 가장 높은 것을 바로 채택하는 것이 아니라, 여러 경우의 수를 생각하여 가장 확률이 높은 문장을 뽑아내는 방식인데, 자세한 내용은 아래의 링크를 보면 되겠다.
[Sooftware 머신러닝] Beam Search (빔서치)
조금 정리하자면, [0.5, 0.49, 0.01] 에서 바로 0.5 를 뽑기보다는 0.49 또한 하나의 선택지로 남겨둔 뒤에, 뒤에 이어질 단어들의 확률을 보고 판단하겠다는 이야기가 된다.
또한, 이 LSTM 을 100-best list 를 rescore 하기 위해 사용했으며, n-best list 를 rescore 하기 위해서는 우리의 모든 추측에 대한 log probability를 계산해 평균을 내는 방식을 사용했다. (3.2 맨 위의 식)
3.3 Reversing the Source Sentences
이 LSTM 모델이 long-term dependencies 문제에도 잘 적용되던 중, LSTM 이 reversed 된 상태로 문장을 학습할 경우, 더 높은 점수를 가진다는 것을 깨달았다.
이 방식으로 학습시켰을 때, LSTM’s test perplexity 는 5.8 에서 4.7 로 줄어들었고, BLEU 점수는 25.9점에서 30.6 점이 되는 높은 향상도를 나타냈다. (여기서 perplexity는 “헷갈리는 정도” 를 뜻하는데, 다음 링크를 보자.)
물론 이 추측에 대한 완벽한 설명은 존재하지 않지만, 앞서 말했듯이 short-term dependencies 들을 만들어 냄으로써 더욱 높은 정확도를 보인 것 같다.
일반적인 상황에서는, 우리가 source 문장과 target 문장의 단어들을 연결시켜 보았을 때, 각 단어쌍들이 일정한 간격으로 떨어져 있음을 알 수 있다. 하지만, reversed 상태로 단어들을 연결시켜 보면, 단어쌍들의 간격을 모두 더한 값은 일정하게 유지되지만, short-term dependencies 을 가지는 단어들이 생겨나기 때문에, minimal time lag 문제를 해소할 수 있다.
또한, 역전파를 시행할 때, “establishing communication” 이 가능해져 연산이 더욱 용이해진다는 장점 또한 존재하기에, 효율적인 아이디어임을 알 수 있다.
3.4 Training details
LSTM 모델은 학습하기 손쉬웠는데, LSTM 을 4개의 layer 을 이용했고, 각 계층마다 1000 개의 cell 을 사용했다. 또한, 1000-dimensional word vector들을 사용했다. 그 결과로 Input sentence 하나를 1개의 벡터로 표현할 때 8000 개의 실수가 사용되었다.
LSTM 모델이 더 깊은 layer 들을 가질수록 더욱 높은 성능을 낸 것을 실험을 통해서도 알고 있었지만 (1개의 layer 가 늘어날 때마다, 10%의 perplexity 가 줄었다.),
그리고 80000 개의 word 들에 대해서 naive 한 softmax를 진행했으며, output layer 의 LSTM 모델은 384M 개의 parameter 이 필요하며, 그중에 64M 개의 parameter 은 순수한 recurrent connection 에서 사용되는 것이다.
** 더 자세한 데이터들은 아래와 같다.

3.5 Parallelization
컴퓨터 병렬연산 부분은 생략.
3.6 Experimental Results
모델을 평가하기 위해서 cased BLEU score 을 사용했다.BLEU score을 이용해서 계산했으며, 그 결과는 아래와 같다.
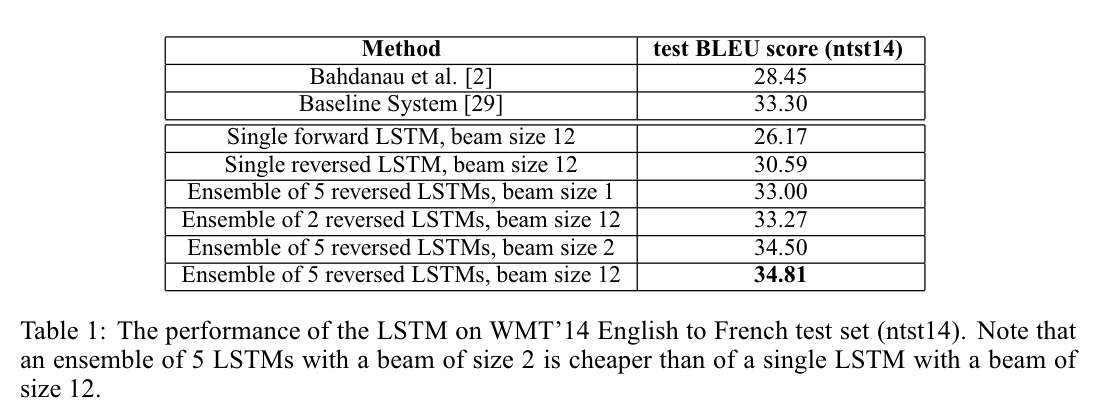

vocab 에 포함되지 않았던 out-of-vocaulary words 들이 있었음에도 불구하고, SOTA 와 0.5 정도밖에 차이가 나지 않았다.
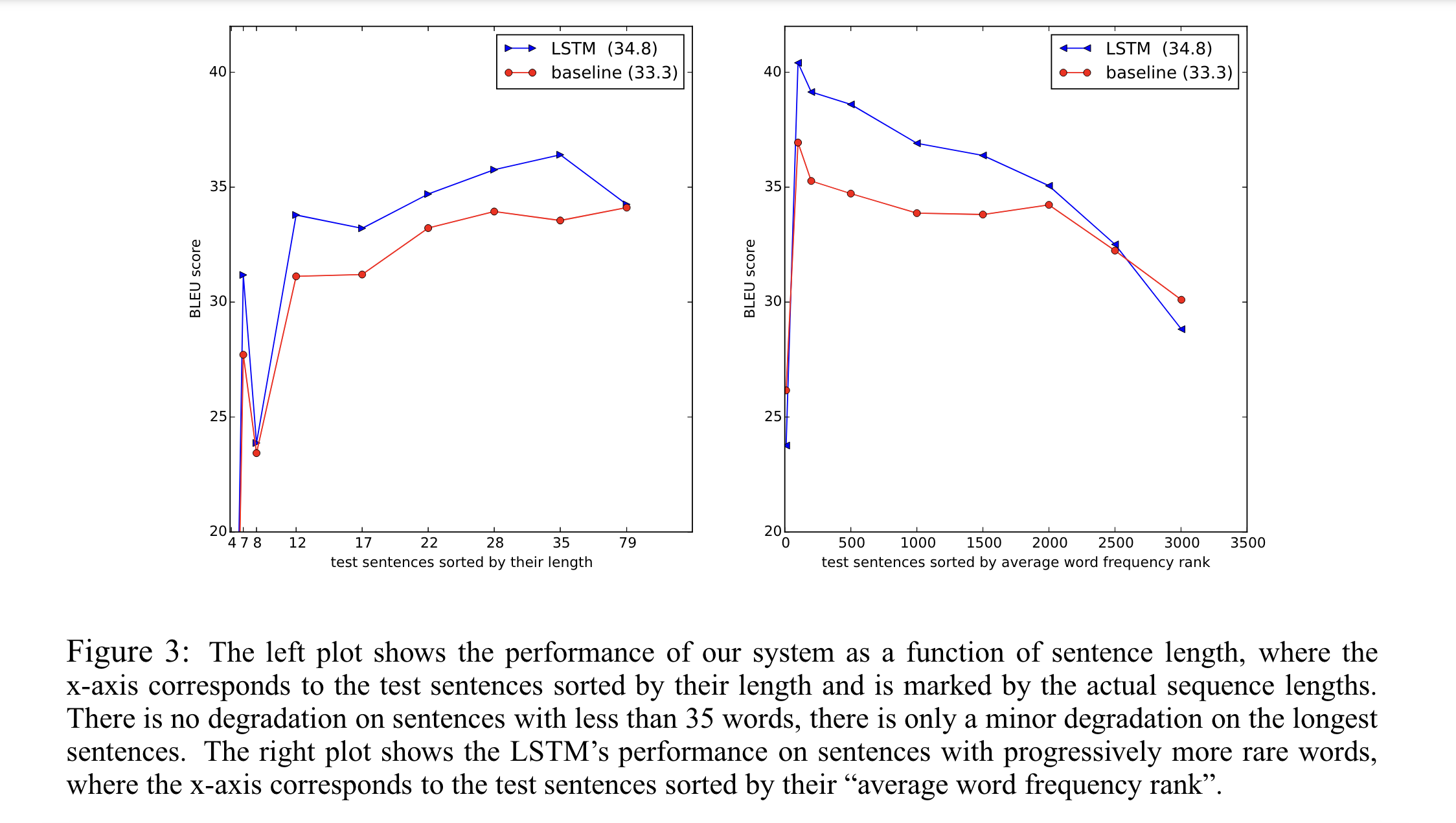
3.7 Performance on long sentences
긴 문장에 대해서도 별다른 어려움을 겪지 않았다. 아래의 그림에 보다시피, sentences의 length 에 큰 차이가 있지 않았으며, 오히려 긴 문장에 대해 점수가 더 높은 것을 볼 수 있다.
3.8 Model Analysis
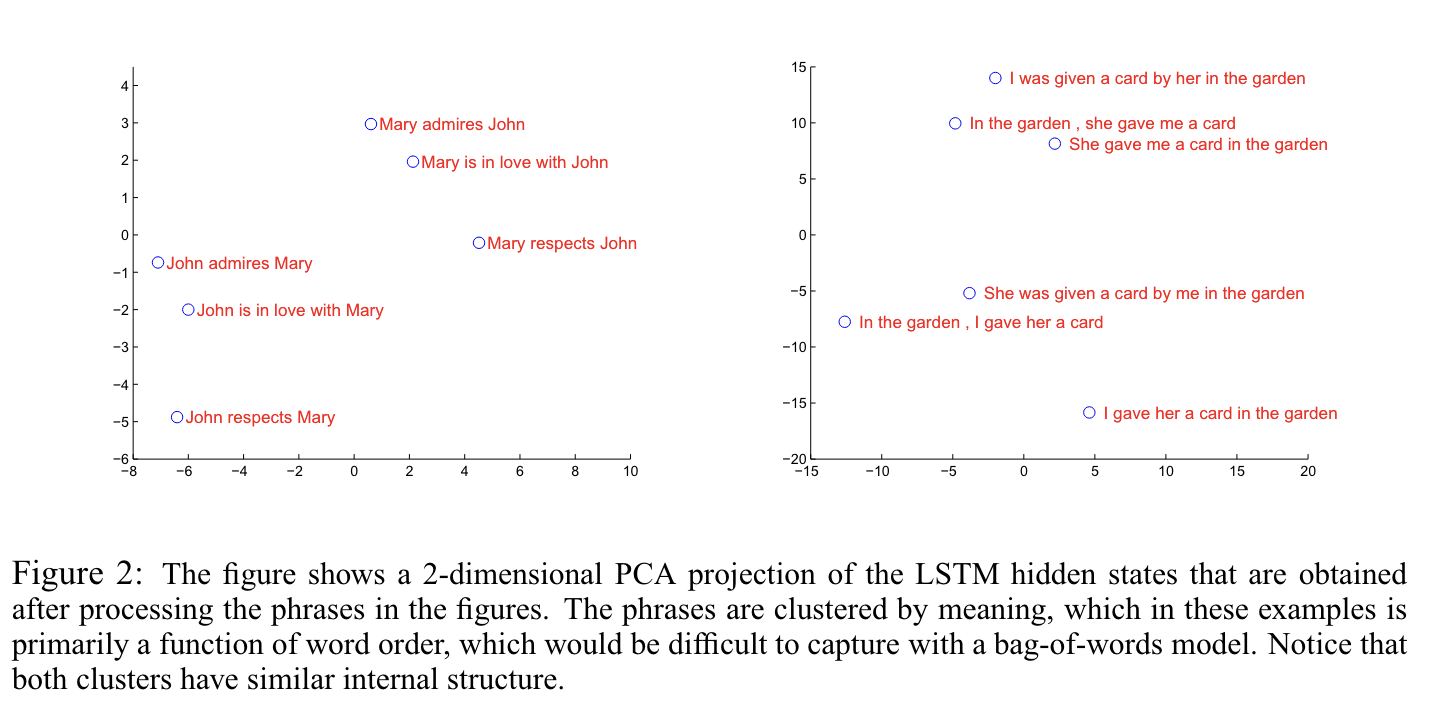
위 그림과 같이, 모든 문장의 구성된 단어가 같음에도 불구하고, sentence 의 order 만 달라도 이렇게 vector 에 차이가 나는 것을 확인할 수 있다.
또한, 서로 다른 문장 구조를 가지고, 수동태나 능동태로 구성된 문장 또한 의미가 유사한 문장들이 vector 상으로 가까운 것을 확인할 수 있다.
4. Related Work
기계 번역에 대해서는 매우 많은 노력들이 있었는데, 그중 가장 간단하면서 효과적인 방식은 RNN 이나 Feedforward-NNLM 을 통해서 n-best list 을 re-scoring 하는 방식이다.
조금 더 최근에는, 학자들이 Source language의 정보를 NNLM 에 포함시키는 방식을 찾기 시작했다.
(예를 들면 Input sentence 의 topic model 을 결합시킨 모델이나, NNLM 을 기계 번역 시스템의 decoder 에 결합하는 등의 시도가 있다.)
그중 본 논문의 방식은 Kalchbrenner and Blunsom 과 연관이 있는데, 여기서는 Input sentence 를 하나의 vector 로 매핑하고, 이 벡터를 다시 Output sentence 로 추출해냈다. 하지만, 이들은 CNN 을 이용해 문장을 임베딩하여 문장의 order 정보를 상실했다.
Cho et al 또한 비슷한 접근을 했는데, vector을 다시 output sentence 로 변환할 때 LSTM-like RNN 을 사용하면서, 긴 문장에 대한 정확도가 급격하게 떨어지는 문제를 겪었다.
이 문제를 해결하기 위해서 Bahdanau et al 은 긴 문장들에 대해서만 attention mechanism을 사용하여 성능을 높이기도 했다.
하지만, 이 논문의 방법은 단순히 source sentence 의 order 을 reverse 해서 학습시키는 것으로 비슷한 수준을 달성해냈다.
5. Conclusion
이 연구에서는, large deep LSTM, 그리고 limited-vocab 을 통해서 SMT-based system (vocab의 limit 가 없는 시스템) 의 성능을 능가했다. 이런 접근 방식을 통해서 MT 뿐만 아니라, 여러 sequenced datset 에 대해서도 학습할 때도 충분히 좋은 아이디어가 될 것이다.
놀라운 점은, 단어들을 reversed 된 형태로 학습시켰을 때 더 좋은 효과를 냈다는 것이며, 실험을 직접 해보진 않았지만 LSTM 이 아닌 RNN 도 마찬가지로 좋은 성능을 낼 것이라고 예상한다.
또한, LSTM 이 긴 문장에 대해서도 효과가 있었다는 것이 놀랍다. 처음에 예상하기로는 LSTM 이 긴 문장에 대해서는 정확도가 다소 떨어질 것이라고 (그리고 이미 유사한 LSTM 모델들이 긴 문장에 대해 정확도가 떨어진 점을 감안하여) 생각했었는데, 이 논문의 LSTM 은 reversed order로 학습했기 때문에 그렇지 않았다.
가장 중요한 점은, SMT 번역의 성능을 능가하는 Simple & StraightForward 방식을 고안해냈다는 것이며, 추후의 연구에서 이보다 더 좋은 성능의 번역 정확도를 보일 것이다.